文本信息检索是针对文本的技术。在技术社区中,文本信息检索常常被等同于信息检索技术本身。
相对视频、音频检索而言,文本信息检索是发展较快也较成熟的,其他模态的信息检索技术,往往也要仰赖文本信息检索的支持。
虽然目前已不仅仅局限于对文本进行检索,文本信息检索仍然是大部分的基础。
目录[] |
[]历史介绍
自人类的文字产生起,如何快速地从大量的,记录在各种各样的存储媒体中查找或获取信息就成为一个引人注目的问题。这个问题关系到人类如何能够主动地获取自己需要的知识。因此,文本信息检索技术甚至可以追述到古代的书籍编目。但是直到近一个世纪,随着人类的知识以前所未有的速度急剧膨胀,信息存储方式越来越丰富,使得在海量的,多模态的信息库中进行快速、准确的检索成为急迫的需求。1945年,Vannevar Bush的论文《就像我们可能会想的……》第一次提出了设计自动的,在大规模的存储数据中进行查找的机器的构想。这被认为是现在信息检索技术的开山之作。进入50年代后,研究者们开始为逐步的实现这些设想而努力。在50年代中期,在利用对文本数据进行检索的研究上,研究者取得了一些成果。其中最有代表性的是Luhn在公司的工作,他提出了利用词对文档构建索引并利用检索与文档中词的匹配程度进行检索 的方法,这种方法就是目前常用的的雏形。
在60年代,信息检索技术的一些关键技术取得了突破。其间出现了一些优秀的系统以及评价指标。在评价指标方面,由Cranfield的研究组组织的Cranfield评测提出了许多目前仍然被广泛采用的评价指标,而在系统方面,Gernard Salton开发的SMART系统构建了一个很好的研究平台,在此平台上,研究者可以定义自己的文档相关性测度,以改进检索性能。这样,作为一个研究课题,信息检索技术拥有了较为完善实验平台与评价指标,其研究理所当然地步入了快车道。也正因为如此,在70年代到80年代,许多信息检索的理论与模型被提出,并且被证明对当时所能获得的数据集是有效的。其中最为著名的是Gerard Salton提出的矢量空间模型 。至今该模型还是信息检索领域最为常用的模型之一。但是,检索的对象——文本集合的缺乏使得这些技术在海量文本上的可靠性无法得到验证。当时的研究大多针对数千篇的组成的集合。这时,美国国家标准技术研究所(NIST)组织的文本检索会议(Text Retrieval Conference, TREC)的召开改变了这一情况。TREC是一个评测性质的会议,为参评者提供了大规模的文本语料,从而大大推动了信息检索技术的快速发展。会议的第一次召开是1992年,不久后,互联网兴起为信息检索技术提供了一个巨大的实验场。从到,大量实用的文本信息检索系统开始出现并得到广泛应用。这些系统从事实上改变了人类获取信息与知识的方式。
目前,在文本检索领域,简单的信息检索已经开始向更加复杂且人性化的演化,引入了信息抽取技术以提取文档中的结构化信息。
[]模型
早期的信息检索系统采用“布尔查询”的方法来进行全文检索。这种方法无疑将构造一个合适的查询的责任推到用户身上。用户必须详细的规划自己的查询,其复杂程度不亚于编程语言。这种检索方式并不提供任何的文档相关性测度,对于文档与查询的评价就只有“匹配”,“不匹配”两种而已。这两点问题决定了布尔查询不能被广泛应用。但是,由于布尔检索能够给用户提供更多的可控制性,今天我们仍然可以在搜索引擎的“高级搜索”中找到布尔查询的身影。
对于大规模的语料库,任何检索都可能返回数量众多的结果,因此对检索结果进行排序是必须的。因此,一个好的信息检索模型必须提供文档相关性测度。一个好的测度应该使与用户查询需求最相关的那些结果,排在最前面,同时允许尽可能多的,与用户查询有一定关系的结果被包括进来。目前,最为常用的信息检索模型有三种:
- 矢量空间模型 (Vector Space Model, VSM)
- 概率模型 (Probabilistic Model)
- 推理网络模型 (Inference Network Model)
[]矢量空间模型
最早由Gerard提出。在此模型中,一个文档(Document)被描述成由一系列关键词(Term)组成的矢量。模型并没有规定关键词如何定义,但是一般来说,关键词可以是字,词或者短语。在中,还可以是混淆类、音子、音子串等等单元。假设我们用“词”作为Term,那么在词典中的每一个词,都定义矢量空间中的一维。如果一篇文档包含这个词,那么表示这个文档的矢量在这个词所定义的维度上应该拥有一个非0值(对绝大多数系统来说,是正值)。
当一个查询被提交时,由于这个查询也是由文本构成,所以也可以被矢量空间所表示。模型将对查询与文档,计算一个相似度需要注意的是,模型也没有对相似度给出确切的定义。它可以使欧氏距离,也可以是两个矢量的夹角的。
假设 表示文档矢量,而
表示文档矢量,而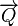 表示查询矢量,文档与查询的相关性可以用余弦距离表示如下:
表示查询矢量,文档与查询的相关性可以用余弦距离表示如下:
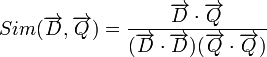
如果我们用 和
和 表示和中的第i维的值,并且对每个文档矢量进行归一化,即令
表示和中的第i维的值,并且对每个文档矢量进行归一化,即令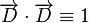 ,那么上式有可以表示为
,那么上式有可以表示为

在此, 究竟如何取值是一个重要的问题,其取值一般被称为关键词i在文档D中的权重。关键词权重问题将在随后进行专门的讨论。
究竟如何取值是一个重要的问题,其取值一般被称为关键词i在文档D中的权重。关键词权重问题将在随后进行专门的讨论。
传统矢量空间模型的一个问题是各个维度间缺乏相关性,因而无法对文档中各个词的相关性提供信息。从宏观上看,仍然没有摆脱“关键词匹配”的窠臼。一个自然的想法就是对文档特征——文档矢量进行降维,将维数巨大的文档矢量投影到某个较小维度的空间中,使得关键词之间即使不完全匹配,也能够根据语义发生关系。这就诞生了潜语义索引(Latent Semantic Indexing),它通过对矢量空间进行奇异值分解,将高维文档矢量投射到低维潜语义空间中。潜语义索引随后被融入概率模型框架中,形成了基于概率模型的PLSI(Probabilistic Latent Semantic Indexing), 和LDA(Latent Dirichlet Allocation)。
[]概率模型
概率模型的基本思想是估计文档与查询相关联概率,并对所有文档根据关联概率进行排序。这一模型最早由Maron和Kuhn在1960年提出。在给定查询Q的情况下,用P(R | D)表示文档与查询相关的概率,而用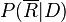 表示文档与查询不相关的概率。 那么,就可以用
表示文档与查询不相关的概率。 那么,就可以用
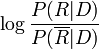
对文档进行排序。利用贝叶斯公式,可以很容易的将上面的公式变为产生式的形式:

由于P(R)和 同文档无关,上面的公式可以最终表示为:
同文档无关,上面的公式可以最终表示为:

概率模型的主要任务就集中在估计P(D | R)和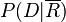 上。
上。
[]推理网络模型
推理网络模型是一种较上述两中模型更为一般化的模型,上述模型都可以归结为推理网络模型的一种实现。在此模型下,仅仅规定文档以某种 “力度”产生某个来自查询的关键词,至于力度如何定义,则完全没有规定,即可以是概率,也可以是关键词权重。
[]倒排文档索引技术
在信息检索系统的具体实现中,需要快速地找到文档中所包含的关键词。相比文档来说,关键词的个数是较少的,因此,以关键词为核心对文档进行索引是更加可行的方法。这就是信息检索领域常用的“倒排文档索引”技术。倒排文档索引可以被看成一个链表数组,每个链表的表头包含关键词,其后续单元则包括所有包括这个关键词的文档标号,以及一些其他信息。这些信息可以是文档中该词的频率,也可以是文档中该词的位置等信息。
倒排文档索引的优势不仅在于关键词个数少带来的检索效率提高,还在于其特别易于同信息检索技术结合。在实际应用中,查询中所包含的关键词往往是很少的,完全不包含查询中的所有关键词的文档,一般来说是不会被列入结果集的。因此,以关键词为主键进行索引,只需要用查询中包括的关键词,进行几次简单的查询就能够找出所有可能的文档。
倒排文档索引的具体数据结构可以进行进一步的优化。在关键词查询上,往往采用B-Tree或进行快速查询。而文档列表的数据结构则可以采用简单的无串行表进行存储,但是此种无串行表存在一个问题,就是当多个关键词对应的文档集需要进行比较的时候,比较效率将比较低。因此,在实际应用中往往采用组织文档列表。
[]关键词权重
关键词对于区分文档的作用是不同的。例如一些虚词对于区分文档的内容与查询是否相关并没有多大的意义。
对于概率模型而言,可以有完备的理论来估计每篇文档生成某个词的概率,因而其主要工作集中于如何确定较好的概率估计方法。而对于矢量 空间模型来说,确定关键词权重在很大程度上依赖于研究者的经验及对文档特性的分析。
目前,对关键词权重的确定方法一般都需要获取一些关于关键词的统计量,而后根据这些统计量,应用某种认为规定的计算公式来得到权重。 最常用的统计量包括:
- tf,Term Frequency的缩写,表示某个关键词在某个文档中出现的频率。
- qtf,Query Term Frequency的缩写。表示查询中某关键词的出现频率。
- N,集合中的文档总数
- df,Document Frequency的缩写,表示文档集合中,出现某个关键词的文档个数。
- idf,Inversed Document Frequency的缩写。

- dl,文档长度
- adl,平均文档长度
在矢量空间模型下,构造关键词权重计算公式有三个基本原则:
- 如果一个关键词在某个文档中出现次数越多,那么这个词应该被认为越重要。
- 如果一个关键词在越多的文档中出现,那么这个词区分文档的作用就越低,于是其重要性也应当相应降低。
- 一篇文档越长,那么其出现某个关键词的次数可能越高,而每个关键词对这个文档的区分作用也越低,相应的应该对这些关键词予以一定的折扣。
得分。严格地说,TF/IDF得分并不特指某个计算公式,而是一个计算公式集合。其中TF与IDF都可以进行各种变换,究竟何种变换较能符合实际需求,需要由实验和应用来验证。常见的变换方法有:
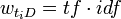
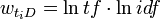
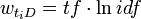 被大量系统证明是最有效的。
被大量系统证明是最有效的。 此外,较为常用的关键词权重算法还包括Okapi权重和Pivoted Normalization 权重(PNW)。这些公式综合考虑了查询和文档中的词频,以及文档的长度。Okapi权重需要预设三个参数:
- k1,在1.0-2.0之间
- b,通常为0.75
- k3,在0-1000之间

而PNW则需要预设一个参数s,大部分情况下取0.20。

[]评价指标
任何研究都需要有一个客观的评价体系,信息检索系统也不例外。但是对于一项需要在实际生产生活中应用的系统,其评价导向又必须包含一定的主观性。信息检索系统性能的两个基本客观指标是召回率(Recall Rate)和准确率(Precision Rate),这与绝大多数的模式识别技术相同。用 表示检索系统所针对的检索集合,Q表示一个查询,而
表示检索系统所针对的检索集合,Q表示一个查询,而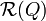 表示查询所返回的相关文档集,
表示查询所返回的相关文档集, 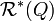 表示文档集中与查询相关的所有文档。并定义算符
表示文档集中与查询相关的所有文档。并定义算符 为集合中元素的个数,有召回率、准确率的定义如下:
为集合中元素的个数,有召回率、准确率的定义如下:
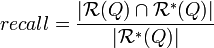

由于信息检索系统返回的是一个排序的文档集合,因此召回率与准确率是互补的。设定不同的相关性得分门限就能够得到相应的准确率与 召回率。如果我们在以准确率为Y轴,召回率为X轴的图上画出不同门限下的准确率与召回率,一般它会程下面的形状:
那么,对于系统的评价指标就存在一个问题,如果一个系统偏重与给用户最准确的结果,那么高的准确率是必要的,反之,如果系统 希望包括尽可能多的相关结果,又会偏好召回率。系统如果简单的用召回率或准确率对系统性能作评价,无法评估系统的理想性能的。
模式识别中常用F值作为性能的评价指标,其定义为
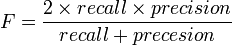
F值可以平衡地反映召回率与准确率,但是在信息检索中仍然不是非常实用,因为它仍然是一个单点的指标,没有反映全局特性。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线分布对应了两个检索系统的准确率-召回率曲线。
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。更加具体的,曲线与坐标轴之间的面积应当越大。最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率(mean Average Precision, mAP)。其规范的定义是,设P(R)为系统在召回率为R时的准确率,

当然,一般在做评价时取得的准确率与召回率都是离散值,因此一般在计算时都采用求和而非积分。
mAP是一个较好的客观评价指标,但是它也有一个缺陷,那就是缺乏直观性。因此在系统评测时常常还是要附带上准确率-召回率曲线。在实际 应用中,还有一些单值评价指标,能够反映系统的主观性能。其中最常用的是N-Best准确率。一般系统的返回结果都采用分页显示,用户一般 不会翻看太多页,因此前几个结果在检索中是最为重要的。N-Best准确率可以很好的反映这个性能。
[]参阅
[]参考文献
- V. Bush, “As We May Think”, Atlantic Monthly, vol. 176, pp. 101–108, 1945
- H.P. Luhn, “A statistical approach to mechanized encoding and searching of literary information”,IBM Journal of Research and Development, vol. 1(4), pp. 309–317, 1957.
- C.W. Cleverdon, “The Cranfield tests on index language devices”, in Aslib Proceedings, vol. 19, pp. 173–192, 1967.
- G. Salton, “The SMART Retrieval System–Experiments in Automatic Document Retrieval”, Tech. Rep., Prentice Hall Inc., Englewood Cliffs, NJ, 1971.
- ^ G. Salton, A. Wong, and C.S. Yang, “A vector space model for information retrieval”, Communications of the ACM, vol. 18(11), pp. 613–620, 1975.
- G. Salton and C. Buckley, “Term-weighting approaches in automatic text retrieval”, Information Processing and Management, vol. 24(5), pp. 513–523, 1988.
- G. Salton and M. J. McGill, Introduction to Modern Information Retrieval, McGraw Hill Book Co., 1983.
- S. Deerwester, S.T. Dumais, G.W. Furnas, T.K. Landauer, and R. Harshman, “Indexing by latent semantic analysis”, Journal of the American Society for Information Science, vol. 41(6), pp. 391–407, 1999.
- T. Hofmann, “Probabilistic latent semantic indexing”, in Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, pp. 50–57, 1999.
- D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation”, J. Mach. Learn. Res., vol. 3, pp. 993–1022, 2003.
- M.E. Maron and J.L. Kuhns, “On relevance, probabilistic indexing and information retrieval”,Journal of the ACM, vol. 7, pp. 216–244, 1960.
- S. E. Robertson, S. Walker, and M. Beaulieu, “Okapi at TREC7, automatic ad hoc, filtering, VLC and filtering tracks”, in Seventh Text REtrieval Conference (TREC-7), pp. 253–264, 1999.
- A. Singhal, J. Choi, D. Hindle, D. Lewis, and F. Pereira, “AT&T at TREC 7”, in Proceedings of the Seventh Text REtrieval Conference (TREC-7), vol. 500, pp. 239–252, 1999.
- 高勤 汉语语音文档检索技术研究及系统实现 北京大学硕士研究生学位论文